
Пример обучения сети APT
В общих чертах сеть обучается посредством изменения весов таким образом, что предъявление сети входного вектора заставляет сеть активизировать нейроны в слое распознавания, связанные с сходным запомненным вектором. Кроме этого, обучение проводится в форме, не разрушающей запомненные ранее образы, предотвращая тем самым временную нестабильность. Эта задача управляется на уровне выбора критерия сходства. Новый входной образ (который сеть не видела раньше) не будет соответствовать запомненным образам с точки зрения параметра сходства, тем самым формируя новый запоминаемый образ. Входной образ, в достаточной степени соответствующий одному из запомненных образов, не будет формировать нового экземпляра, он просто будет модифицировать тот, на который он похож. Таким образом при соответствующем выборе критерия сходства предотвращается запоминание ранее изученных образов и временная нестабильность.
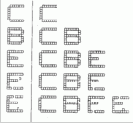
Рис. 8.6. Процесс обучения APT
На рис. 8.6 показан типичный сеанс обучения сети APT. Буквы показаны состоящими из маленьких квадратов, каждая буква размерностью 8x8. Каждый квадрат в левой части представляет компоненту вектора Х с единичным значением, не показанные квадраты являются компонентами с нулевыми значениями. Буквы справа представляют запомненные образы, каждый является набором величин компонент вектора Тj.
Вначале на вход заново проинициированной системы подается буква «С». Так как отсутствуют запомненные образы, фаза поиска заканчивается неуспешно; новый нейрон выделяется в слое распознавания, и веса Тj устанавливаются равными соответствующим компонентам входного вектора, при этом веса Вj представляют масштабированную версию входного вектора.
Далее предъявляется буква «В». Она также вызывает неуспешное окончание фазы поиска и распределение нового нейрона. Аналогичный процесс повторяется для буквы «Е». Затем слабо искаженная версия буквы «Е» подается на вход сети. Она достаточно точно соответствует запомненной букве «Е», чтобы выдержать проверку на сходство, поэтому используется для обучения сети. Отсутствующий пиксель в нижней ножке буквы «Е» устанавливает в 0 соответствующую компоненту вектора С, заставляя обучающий алгоритм установить этот вес запомненного образа в нуль, тем самым воспроизводя искажения в запомненном образе. Дополнительный изолированный квадрат не изменяет запомненного образа, так как не соответствует единице в запомненном образе.
Четвертым символом является буква «Е» с двумя различными искажениями. Она не соответствует ранее запомненному образу (S меньше чем r), поэтому для ее запоминания выделяется новый нейрон.
Этот пример иллюстрирует важность выбора корректного значения критерия сходства. Если значение критерия слишком велико, большинство образов не будут подтверждать сходство с ранее запомненными и сеть будет выделять новый нейрон для каждого из них. Это приводит к плохому обобщению в сети, в результате даже незначительные изменения одного образа будут создавать отдельные новые категории. Количество категорий увеличивается, все доступные нейроны распределяются, и способность системы к восприятию новых данных теряется. Наоборот, если критерий сходства слишком мал, сильно различающиеся образы будут группироваться вместе, искажая запомненный образ до тех пор, пока в результате не получится очень малое сходство с одним из них.
К сожалению, отсутствует теоретическое обоснование выбора критерия сходства, в каждом конкретном случае необходимо решить, какая степень сходства должна быть принята для отнесения образов к одной категории. Границы между категориями часто неясны, и решение задачи для большого набора входных векторов может быть чрезмерно трудным.
В работе [2] предложена процедура с использованием обратной связи для настройки коэффициента сходства, вносящая, однако, некоторые искажения в результате классификации как «наказание» за внешнее вмешательство с целью увеличения коэффициента сходства. Такие системы требуют правил определения, является ли производимая ими классификация корректной.